World Tree
The viewer stores data in a hierarchical fashion inside a tree-like structure which we call WorldTree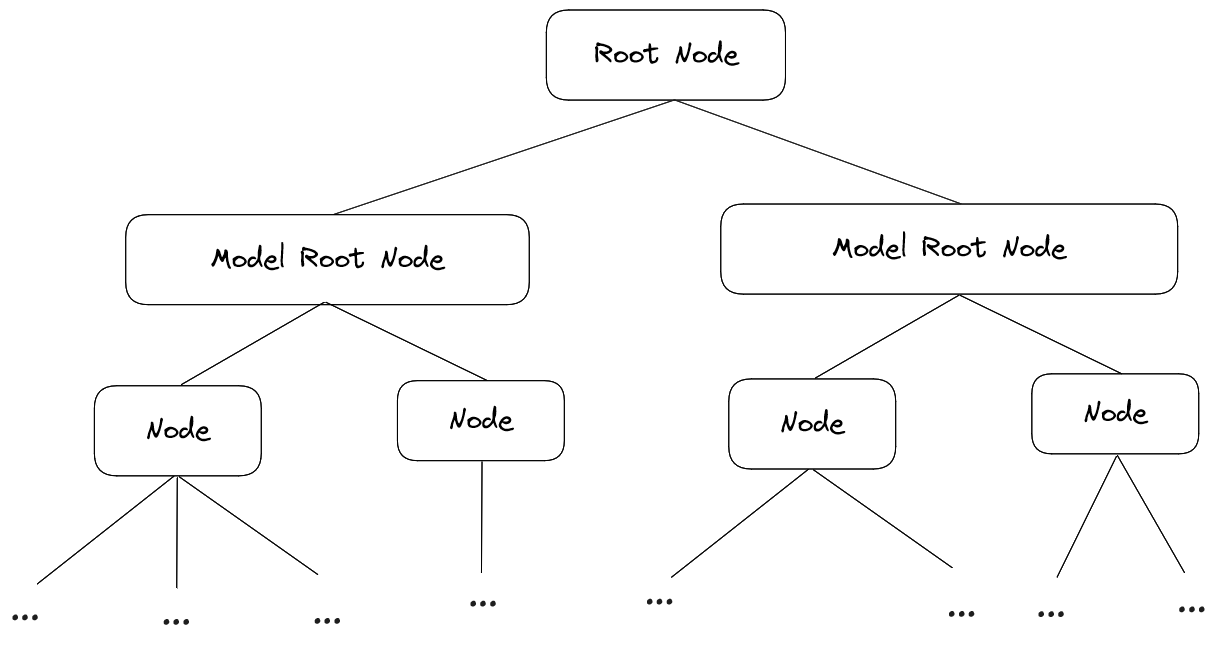
NodeData model payload of a Node:
raw data that came in via the loader. In the SpeckleLoder’s case it’s the actual speckle object. The atomic property hints at whether we need to treat this node as a complete object (true) or just being part of another object (false). subtreeId is just an internally used property for search acceleration, and instanced tells if this node data is being used by multiple nodes. The renderView property is a very important property which holds the data required for everything rendering related. We will describe it in detail later on.
The WorldTree class provides functionality for adding, removing ,searching and walking the tree. It is the single source of truth for all the data in the viewer and it’s the place to go for all data related operations.
Working with Nodes
The TreeNodes in the WorldTree are nothing else than the objects you loaded in. So at some point, you want to interact with your objects on one level or another. Typically, there are two ways to get hold of nodes.ID-based:
findId returns an array rather than a single node. That’s because the speckle viewer does not assume a 1:1 relationship between an id and a node/object. A good example for this is instances: when provided with the id of an instance, findId will return all the instance nodes. Outside of this scenario, findId will return an array of one node.
A more specific way of using findId is
subtreeId, only that subtree will be searched. To disambiguate the term subtree: Each time you load something via loadObject that data will be stored in it’s own subtree with a unique id. Specifying an explicit subtreeId comes in handy in scenarios where you have multiple loaded resources, with identical objects between them, for example several versions of the same model.
Generic:
Due to lack of better wording, this is basically any object query you’d do that does not imply specific object ids. So for example you’d want to get nodes which satisfy a specific condition:World Tree Walk
false from the predicate of either walk or walkAsync will stop the walking immediately